
In this article, we will explore the process of extracting data from an AWS RDS database, and then publishing it to S3. We will cover the following details:
- The ability to support data stored in Amazon Aurora and all other Amazon RDS engines, Amazon Redshift, and Amazon S3 (such as XML, CSV format)
- Big data size
- Different data schemas
- A solution to easily switch environments from Development → Test → User Acceptance Testing (UAT) → Staging → Production
- Autoscale hardware related to data size
After researching several solutions, I chose to utilize AWS Glue because it is the ETL service provided by AWS. It has three main components, which are Data Catalogue, Crawler, and ETL Jobs.
- Crawler helps you to extract information (schema and statistics) from your data.
- Data Catalogue is used for centralized metadata management.
- ETL Jobs allow you to process the data stored on AWS data stores with either Glue proposed scripts or custom scripts, with additional libraries and jars.
To get started, we need to design the architecture. You can follow my architecture for the ETL pipeline as below:
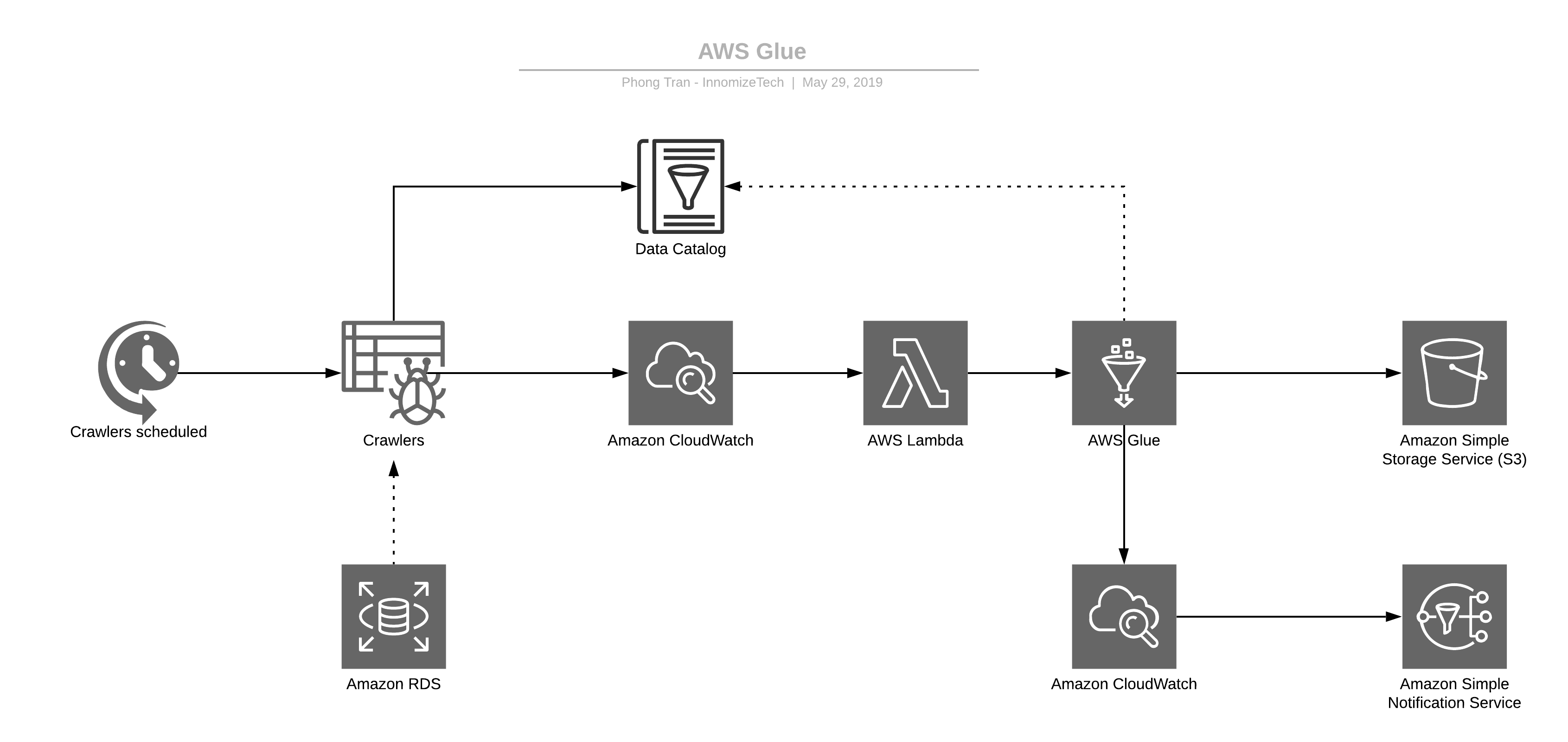
Architecture for the ETL pipeline
For my purposes, I have a schedule that runs daily at 1 AM that starts AWS Crawler to generate the schema for our semi-structured data.
In this example, I use the AWS RDS to flatten the data; however, if the data is mostly multilevel-nested such as XML, then use Glue PySpark Transforms to flatten the data or use Data bricks Spark-XML.
Once the data is cataloged, a cloud-watch event will trigger Lambda to start the Glue job. Python or Scala script will transform the data as we need it, then publish it to S3.
Another cloud-watch event is then setup to notify the support team of the status of the job.
We are looking for an automated way for quick deployment in other environments. Next, we will go through the process of defining a Cloud Formation template in order to create all of the necessary resources (Assumption: the data stores are in a private subnet of VPC).
1. Setting Up Your Environment to Access Data Stores.
The AWS Glue should sit in a private subnet to run your extract, transform, and load (ETL) jobs, but it also needs to access Amazon S3 from within VPC, and then upload the report file. So, a VPC endpoint is required.
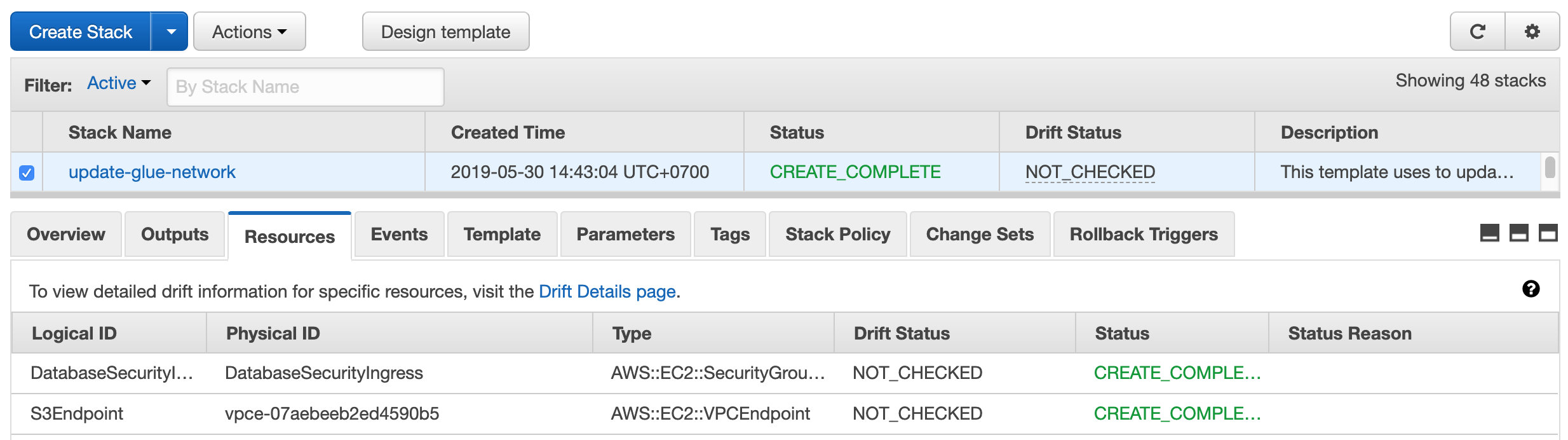
The above template will create an S3 Endpoint resource and update a Security Group to allow all ports to be self-referent.
When the above stack is ready, check the resource tab and find the details.
2. Populating the AWS Glue resources.
Based on the above architecture, we need to create some resources i.e: AWS Glue connection, database (catalog), crawler, job, trigger, and the roles to run the Glue job.
When the stack is ready, check the resource tab; all of the required resources are created as below.
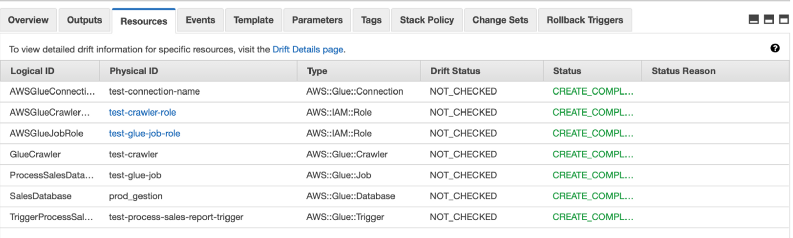
Note: You must upload the Glue Job script into the S3 path that you specify in the cloud formation template.
3. Monitoring AWS Glue Using Amazon CloudWatch Metrics.
AWS noted: You can profile and monitor AWS Glue operations using AWS Glue job profiler. It collects and processes raw data from AWS Glue jobs into readable, near real-time metrics stored in Amazon CloudWatch. These statistics are retained and aggregated in CloudWatch so that you can access historical information for a better perspective on how your application is performing.
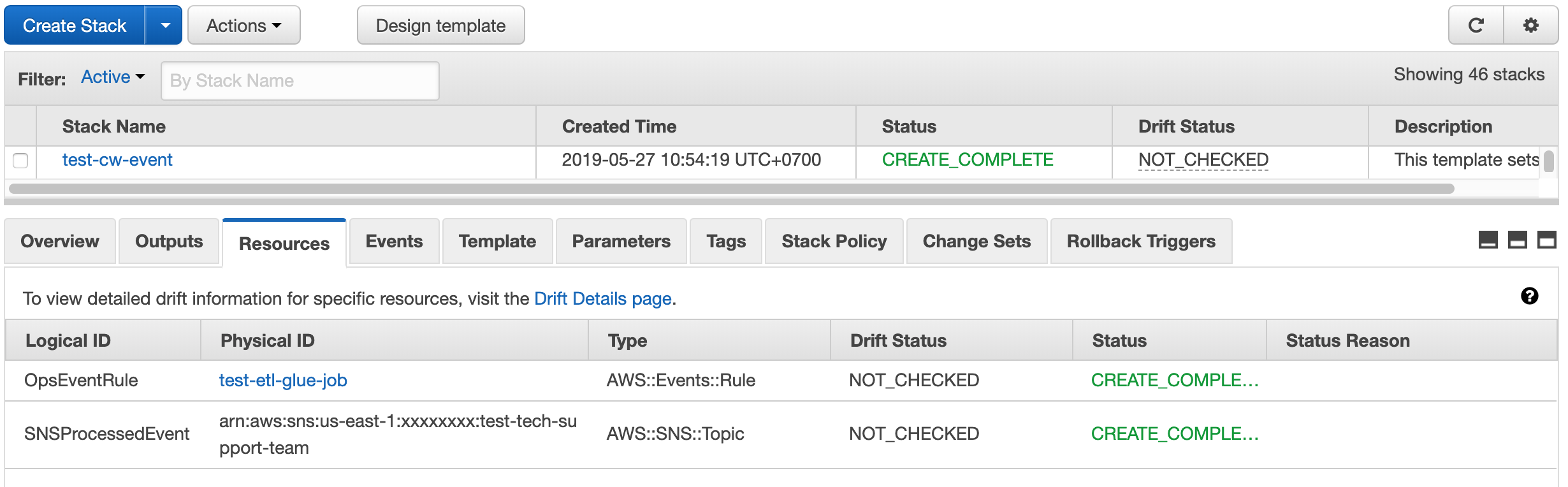
With the Amazon CloudWatch Metric, you can create a cloud watch event rule and trigger an SNS topic to send an email about the job state; and, send a message regarding the result of the job.
When the stack is ready, check the resource tab as seen below:
Now that you have set up an entire data pipeline, in an automated way, with the appropriate notifications and alerts, it is time to test your pipeline. Good luck!